
Fala Nerds e fala Coders!
Há alguns anos o termo microservices (ou no português é chamado de MicroServiços) tem sido muito procurado na área de desenvolvimento de software e alguns desenvolvedores tem citado que esse termo é usado pra descrever uma filosofia de design de arquitetura de software. Embora não exista uma definição precisa, há características comuns entre as implementações que alegam utilizá-la.
Ao analisar os microservices, vemos que eles alcançaram rapidamente o topo do mundo de desenvolvimento de software e desempenham um papel importante em muitas organizações de hoje em dia. Portanto se você entrou neste artigo, provavelmente é porque está procurando algum artigo referente a microservices e hoje resolvi escrever um post para explicar no detalhe dessa arquitetura.
O que é uma arquitetura de microservices resumida?
Segundo o Martin Fowler, ele cita que o termo de “Arquitetura de microserviços” surgiu nos últimos anos para descrever uma maneira particular de projetar aplicativos de software como conjuntos de serviços implantáveis independentemente.
The term “Microservice Architecture” has sprung up over the last few years to describe a particular way of designing software applications as suites of independently deployable services. While there is no precise definition of this architectural style, there are certain common characteristics around organization around business capability, automated deployment, intelligence in the endpoints, and decentralized control of languages and data. — Martin Fowler
Então uma arquitetura de microservices adota essa mesma abordagem e a estende aos serviços fracamente acoplados que podem ser desenvolvidos, implantados e mantidos de forma independente. Cada um desses serviços é responsável por tarefas distintas e pode se comunicar com outros serviços por meio de APIs simples para resolver um problema de negócios complexo maior.
Principais benefícios de uma arquitetura de microservices
Um microservice consiste em um conjunto de endpoints que são responsáveis por prover operações dentro de um domínio específico de informação. Seguem abaixo alguns dos benefícios:
- A segregação da aplicação por domínio de informação permite escalabilidade individual de cada micro serviço.
- A independência dos microservices permite que a aplicação continue funcionando caso ocorra erro em algum serviço, ou seja, apenas alguma funcionalidade ficará indisponível ao invés de toda aplicação.
- Agilidade no deploy de novas funcionalidades.
- Permite trabalhar com diferentes tecnologias por micro service.
Características básicas que você precisa saber sobre a arquitetura de microservices
É importante saber as características mais importantes que cada micro serviço deve contemplar:
- Possuir sua própria base de dados.
- Ter independência dos demais para desenvolvimento e para realização de deploy.
- Possuir autorização em nível de serviço utilizando protocolos como por exemplo OAuth e JWT.
- A comunicação entre microservices deverá ser realizada sempre via exposição de API REST e/ou via publicação de eventos de negócio utilizando recursos de Message Broker.
- Possuir endpoints para health check e Metrics para que os sistemas de monitoramento coletem informações sobre a saúde do micro serviço.
- Realizar requisições assíncronas sempre que possível.
- Os microservices devem possuir a documentação da API REST em um único local compartilhado, utlizando padrões como por exemplo o Swagger.
- Os microservices devem gerar seus logs em um único repositório centralizado. Pode ser realizado via integração com o serviço de logs ou então através de agentes que irão coletar os logs do servidor e enviá-los para o repositório.
Como faço para começar a usar uma arquitetura de microservices?
Conforme mencionado acima, vimos os prós de utilizar arquitetura em microservices. Com isto, começam a surgir perguntas “Como faço para começar?” — e — “Existe um conjunto padrão de princípios que posso seguir para me ajudar a construir uma arquitetura de microservices de uma maneira melhor?”
Bom Nerd e Coder, receio que a resposta não seja a que está esperando que é : “Não”
Embora isso possa parecer não tão promissor, existem, no entanto, alguns temas comuns que muitas organizações que adotaram arquiteturas de microservices seguiram e com os quais, no final das contas, obtiveram sucesso. Vou discutir alguns desses temas comuns a seguir.
1. Como decompor
Uma das maneiras de tornar nosso trabalho mais fácil poderia ser definir serviços correspondentes às capacidades de negócios. Uma capacidade de negócios é algo que uma empresa faz para fornecer valor aos usuários finais.
A identificação de recursos de negócios e serviços correspondentes requer um conhecimento de alto nível dos negócios. Por exemplo, os recursos de negócios para um aplicativo de compras online podem incluir o seguinte.
● Gerenciamento do Catálogo de Produtos
● Gerenciamento de estoque
● Gerenciamento de pedidos
● Gestão de entrega
● Gerenciamento de usuários
● Recomendações de produtos
● Gerenciamento de avaliações de produtos
Depois que os recursos de negócios forem identificados, os serviços necessários podem ser construídos correspondendo a cada um desses recursos de negócios identificados.
Cada serviço pode pertencer a uma equipe diferente, que se torna um especialista naquele domínio específico e um especialista nas tecnologias mais adequadas para esses serviços específicos. Isso geralmente leva a limites de API mais estáveis e equipes mais estáveis.
2. Criação e implantação
Depois de decidir sobre os limites de serviço desses pequenos serviços, eles podem ser desenvolvidos por uma ou mais pequenas equipes usando as tecnologias mais adequadas para cada propósito. Por exemplo, você pode escolher construir um Serviço de usuário em Java com um banco de dados MySQL e um Serviço de recomendação de produto com Scala / Spark.
Depois de desenvolvidos, os pipelines de CI / CD podem ser configurados com qualquer um dos servidores CI disponíveis (Jenkins, TeamCity, Go, etc.) para executar os casos de teste automatizados e implantar esses serviços de forma independente em diferentes ambientes (integração, controle de qualidade, teste, produção , etc).
3. Projete os serviços individuais com cuidado
Ao projetar os serviços, defina-os cuidadosamente e pense no que será exposto, quais protocolos serão usados para interagir com o serviço, etc.
É muito importante ocultar qualquer complexidade e detalhes de implementação do serviço e expor apenas o que é necessário para os clientes do serviço. Se detalhes desnecessários forem expostos, será muito difícil alterar o serviço posteriormente, pois haverá muito trabalho árduo para determinar quem está contando com as várias partes do serviço. Além disso, uma grande flexibilidade é perdida ao ser capaz de implantar o serviço de forma independente.
O diagrama abaixo mostra um dos erros comuns no projeto de microservices:

Como você pode ver no diagrama, aqui estamos pegando um serviço (Serviço 1) e armazenando todas as informações necessárias para o serviço em um banco de dados. Quando outro serviço (Serviço 2) é criado e precisa dos mesmos dados, acessamos esses dados diretamente do banco de dados.
Essa abordagem pode parecer razoável e lógica em certos casos — talvez seja fácil acessar dados em um banco de dados SQL ou gravar dados em um banco de dados SQL ou talvez as APIs necessárias para o Serviço 2 não estejam disponíveis.
Assim que essa abordagem é adotada, o controle é imediatamente perdido para determinar o que está oculto e o que não está. Posteriormente, se o esquema precisar ser alterado, a flexibilidade para fazer essa alteração será perdida, pois você não saberá quem está usando o banco de dados e se a alteração interromperá o Serviço 2 ou não.
Uma abordagem alternativa, e eu apresentaria a maneira certa de lidar com isso, está abaixo:

O serviço 2 deve acessar o serviço 1 e evitar ir diretamente para o banco de dados, preservando, portanto, o máximo de flexibilidade para várias alterações de esquema que podem ser necessárias. A preocupação com outras partes do sistema é eliminada, desde que você certifique-se de que os testes de APIs expostos sejam aprovados.
Conforme mencionado, escolha cuidadosamente os protocolos de comunicação entre os serviços. Por exemplo, se o Java RMI for escolhido, não apenas o usuário da API estará restrito a usar uma linguagem baseada em JVM, mas, além disso, o protocolo em si é bastante frágil porque é difícil manter a compatibilidade com versões anteriores com a API.
Por último, ao fornecer bibliotecas de cliente para que os clientes usem o serviço, pense nisso com cuidado, porque é melhor evitar a repetição do código de integração. Se esse erro for cometido, ele também pode restringir as alterações feitas na API se os clientes dependerem de detalhes desnecessários.
4. Descentralize as coisas
Existem organizações que tiveram sucesso com microservices e seguiram um modelo em que as equipes que constroem os serviços cuidam de tudo relacionado a esse serviço. São eles que desenvolvem, implantam, mantêm e dão suporte. Não há equipes separadas de suporte ou manutenção.
Outra maneira de conseguir o mesmo é ter um modelo de código aberto interno. Ao adotar essa abordagem, o desenvolvedor que precisa de mudanças em um serviço pode verificar o código, trabalhar em um recurso e enviar ele mesmo um PR, em vez de esperar que o proprietário do serviço pegue e trabalhe nas mudanças necessárias.
Para que este modelo funcione corretamente, a documentação técnica adequada é necessária junto com as instruções de configuração e orientação para cada serviço, de modo que seja fácil para qualquer pessoa pegar e trabalhar no serviço.
Outra vantagem oculta dessa abordagem é que ela mantém os desenvolvedores focados na escrita de código de alta qualidade, pois sabem que outras pessoas estarão olhando para ele.
Existem também alguns padrões arquitetônicos que podem ajudar na descentralização das coisas. Por exemplo, você pode ter uma arquitetura em que a coleção de serviços se comunica por meio de um barramento de mensagem central.
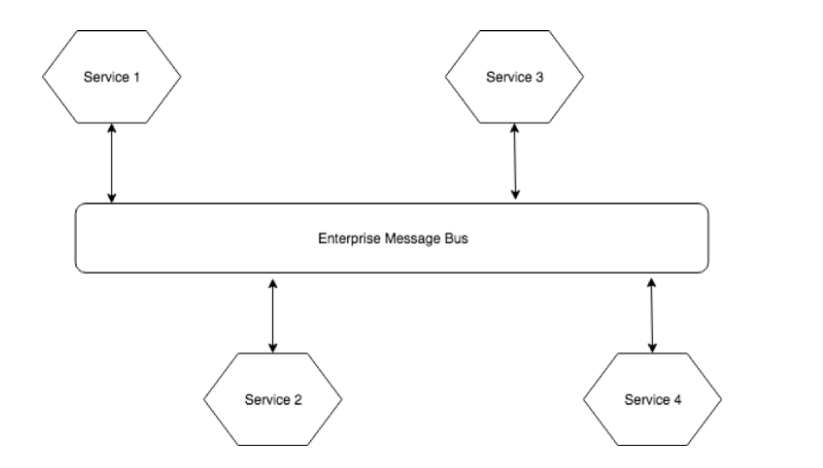
Este barramento controla o roteamento de mensagens de diferentes serviços. Corretores de mensagens como RabbitMQ e Kafka são um bom exemplo.
O que tende a acontecer com o tempo é que as pessoas começam a colocar mais e mais lógica nesse barramento central e ele começa a saber mais e mais sobre o seu domínio. À medida que se torna mais inteligente, isso pode se tornar um problema, pois se torna difícil fazer alterações que exigem coordenação entre equipes dedicadas separadas.
Meu conselho geral para esses tipos de arquiteturas seria mantê-los relativamente “burros” e deixá-los apenas lidar com o roteamento. As arquiteturas baseadas em eventos parecem funcionar muito bem nesses cenários.
5. Implantar
É importante escrever contratos orientados ao consumidor para qualquer API da qual dependemos. Isso é para garantir que novas mudanças nessa API não quebrem sua API.
Em Contratos Orientados ao Consumidor, cada API do consumidor captura suas expectativas do provedor em um contrato separado. Todos esses contratos são compartilhados com o fornecedor para que ele tenha uma visão das obrigações que deve cumprir para cada cliente individual.
Os Contratos Orientados ao Consumidor devem passar completamente antes de serem implantados e antes de quaisquer alterações serem feitas na API. Também ajuda o provedor a saber quais serviços dependem dele e como outros serviços dependem dele.
Quando se trata de implantação de microservices independentes, existem dois modelos comuns.
Vários microservices por sistema operacional
Primeiro, vários microservices por sistema operacional podem ser implantados. Com esse modelo, você economiza tempo na automação de certas coisas, por exemplo, o host de cada serviço não precisa ser provisionado.
A desvantagem dessa abordagem é que ela limita a capacidade de alterar e dimensionar serviços de forma independente. Também cria dificuldade em gerenciar dependências. Por exemplo, todos os serviços no mesmo host terão que usar a mesma versão de Java se forem escritos em Java. Além disso, esses serviços independentes podem produzir efeitos colaterais indesejados para outros serviços em execução, que podem ser um problema muito difícil de reproduzir e resolver.
Um microsserviço por sistema operacional
Por causa do desafio acima, o segundo modelo, onde um microservice por sistema operacional é implantado, é a escolha preferível.
Com esse modelo, o serviço fica mais isolado e, portanto, é mais fácil gerenciar dependências e escalar serviços de forma independente. Mas você pode se perguntar “não é caro”? Bem, na verdade não.
A solução tradicional para resolver esse problema é usar hipervisores, por meio dos quais várias máquinas virtuais são provisionadas no mesmo host. Essa abordagem de solução pode ser ineficiente em termos de custo, pois o próprio processo do hipervisor está consumindo alguns recursos e, é claro, quanto mais VMs forem provisionadas, mais recursos serão consumidos. E é aí que o modelo de contêiner obtém boa tração e é o preferido. Docker é uma implementação desse modelo.
Fazendo alterações em APIs de microsserviço existentes durante a produção
Outro problema comum normalmente enfrentado com um modelo de microsserviço é determinar como fazer alterações nas APIs de microsserviço existentes quando outros o estão usando na produção. Fazer alterações na API de microsserviço pode interromper o microsserviço que depende dele.
Existem diferentes maneiras de resolver esse problema.
Primeiro, crie uma versão de sua API e, quando forem necessárias alterações para a API, implante a nova versão da API enquanto mantém a primeira versão atualizada. Os serviços dependentes podem ser atualizados em seu próprio ritmo para usar a versão mais recente. Depois que todos os serviços dependentes são migrados para usar a nova versão do microsserviço alterado, ele pode ser desativado.
Um problema com essa abordagem é que se torna difícil manter as várias versões. Quaisquer novas alterações ou correções de bugs devem ser feitas em ambas as versões.
Por esse motivo, uma abordagem alternativa pode ser considerada em que outro ponto de extremidade é implementado no mesmo serviço quando as mudanças são necessárias. Assim que o novo ponto de extremidade estiver sendo totalmente utilizado por todos os serviços, o ponto de extremidade antigo pode ser excluído.
A vantagem distinta dessa abordagem é que é mais fácil manter o serviço, pois sempre haverá apenas uma versão da API em execução.
6. Fazendo padrões
Quando há várias equipes cuidando de serviços diferentes de forma independente, é melhor introduzir alguns padrões e práticas recomendadas — tratamento de erros, por exemplo. Como era de se esperar, os padrões e as práticas recomendadas não são fornecidos, cada serviço provavelmente trataria os erros de maneira diferente e, sem dúvida, uma quantidade significativa de código desnecessário seria escrita.
A criação de padrões como o Guia de estilo de API do PayPal é sempre útil a longo prazo. Também é importante permitir que outras pessoas saibam o que uma API faz e a documentação da API sempre deve ser feita ao criá-la. Existem ferramentas como o Swagger, que são muito úteis para auxiliar no desenvolvimento em todo o ciclo de vida da API, desde o design e documentação até o teste e a implantação. A capacidade de criar metadados para sua API e permitir que os usuários brinquem com ela, permite que eles saibam mais sobre ela e a utilizem de maneira mais eficaz.
Dependências de serviço
Em uma arquitetura de microservices, com o tempo, cada serviço começa dependendo de mais e mais serviços. Isso pode introduzir mais problemas à medida que os serviços aumentam, por exemplo, o número de instâncias de serviço e seus locais (host + porta) podem mudar dinamicamente. Além disso, os protocolos e o formato em que os dados são compartilhados podem variar de serviço para serviço.
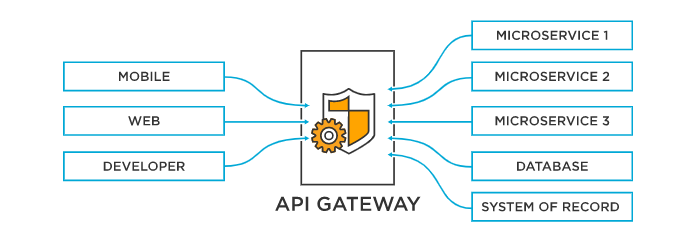
É aqui que os gateways de API e a descoberta de serviços se tornam muito úteis. A implementação de um API Gateway torna-se um único ponto de entrada para todos os clientes e os API Gateways podem expor uma API diferente para cada cliente.
O gateway de API também pode implementar segurança, como verificar se o cliente está autorizado a executar a solicitação. Existem algumas ferramentas como o Zookeeper que podem ser usadas para Service Discovery (embora não tenha sido criado para esse propósito). Existem ferramentas muito mais modernas, como o etcd e o Cônsul da Hashicorp, que tratam o Service Discovery como um cidadão de primeira classe e, definitivamente, vale a pena examinar esse problema.
7. Falha
Um ponto importante a entender é que os microservices não são resilientes por padrão. Haverá falhas nos serviços. As falhas podem acontecer devido a falhas nos serviços dependentes. Além disso, as falhas podem surgir por uma variedade de razões, como bugs no código, tempo limite de rede, etc.
O que é crítico com uma arquitetura de microservices é garantir que todo o sistema não seja afetado ou caia quando há erros em uma parte individual do sistema.
Existem padrões como anteparo e disjuntor que podem ajudá-lo a obter uma melhor resiliência.
Antepara
O padrão Bulkhead isola elementos de um aplicativo em pools para que, se um falhar, os outros continuarão a funcionar. O padrão é cunhado Antepara porque se assemelha às partições seccionadas do casco de um navio. Se o casco de um navio for comprometido, apenas a seção danificada se enche de água, o que impede o navio de afundar.
Disjuntor
O padrão do disjuntor envolve uma chamada de função protegida em um objeto de disjuntor, que monitora as falhas. Uma vez que uma falha cruza o limite, o disjuntor desarma e todas as chamadas adicionais para o disjuntor retornam com um erro, sem que a chamada protegida seja feita para um determinado timeout configurado.
Depois que o tempo limite expira, algumas chamadas são permitidas pelo disjuntor e, se forem bem-sucedidas, o disjuntor retorna ao estado normal. Durante o período de falha do disjuntor, os usuários podem ser notificados de que uma determinada parte do sistema está quebrada e o resto do sistema ainda pode ser usado.
Esteja ciente de que fornecer o nível necessário de resiliência para um aplicativo pode ser um desafio multidimensional — dê uma olhada na postagem de Bilgin Ibryam para obter alguns detalhes importantes “ É preciso mais do que um disjuntor para criar um aplicativo resiliente ”.
8. Monitoramento e registro
Os microservices são distribuídos por natureza e o monitoramento e o registro de serviços individuais podem ser um desafio. É difícil analisar e correlacionar os logs de cada instância de serviço e descobrir erros individuais. Assim como acontece com os aplicativos monolíticos, não há um único local para monitorar microservices.
Agregação de Log
Para resolver esses problemas, uma abordagem preferencial é aproveitar as vantagens de um serviço de registro centralizado que agrega registros de cada instância de serviço. Os usuários podem pesquisar esses logs de um ponto centralizado e configurar alertas quando certas mensagens aparecem.
Ferramentas padrão estão disponíveis e são amplamente utilizadas por várias empresas. ELK Stack é a solução usada com mais frequência, onde o daemon de registro, Logstash , coleta e agrega registros que podem ser pesquisados por meio de um painel Kibana indexado pelo Elasticsearch.
Agregação de estatísticas
Semelhante à agregação de log, a agregação de estatísticas, como uso de CPU e memória, também pode ser aproveitada e armazenada centralmente. Ferramentas como o Graphite fazem um bom trabalho enviando para um repositório central e armazenando de maneira eficiente.
Quando um dos serviços downstream é incapaz de lidar com solicitações, deve haver uma maneira de acionar um alerta e é aí que a implementação de APIs de verificação de integridade em cada serviço se torna importante — elas retornam informações sobre a integridade do sistema.
Um cliente de verificação de integridade, que pode ser um serviço de monitoramento ou um balanceador de carga, chama o terminal para verificar a integridade da instância de serviço periodicamente em um determinado intervalo de tempo. Mesmo se todos os serviços downstream estiverem íntegros, ainda pode haver um problema de comunicação downstream entre os serviços. Ferramentas como o projeto Hystrix da Netflix permitem identificar esses tipos de problemas.
Afinal faz sentido adotarmos a arquitetura de microservices?
Levando em consideração os benefícios que vimos, vale a pena refletirmos se faz sentido adotarmos o microservices como arquitetura em nossos projetos.
Ao se cogitar o uso da arquitetura microservices, embora haja vantagens nítidas, também há custos. O peso de cada contra e de cada pró varia de acordo com a estrutura organizacional da empresa; do domínio, da maturidade e conhecimento do time de outros fatores de difícil ponderação que afetam esse balanço.
A verdade é que não é incomum que a balança pese mais para a não utilização de microservices.
No fim das contas, a familiaridade do time com a solução é um dos pontos mais importantes, seja ela feita em arquitetura de microservices ou seja ela em uma arquitetura monólito.
Referências
- The Twelve-Factor App
- Microservices — Martin Fowler
- Microservice Architecture Pattern
- Does My Bus Look Big in This?
- https://developers.redhat.com/blog/2017/05/16/it-takes-more-than-a-circuit-breaker-to-create-a-resilient-application/
- https://medium.com/xp-inc/entendendo-a-arquitetura-de-microservices-cdab6b52d6ed
