Posted on: January 29, 2020 12:18 PM
Posted by: Renato
Categories: Variados
Views: 344
Por Jonathan Calmels , Felix Abecassis e Pramod Ramarao |

A NVIDIA usa contêineres para desenvolver, testar, avaliar e implantar estruturas de aprendizagem profunda (DL) e aplicativos HPC. Escrevemos sobre a criação e implantação de contêineres de GPU em escala usando o NVIDIA-Docker há aproximadamente dois anos. Desde então, o NVIDIA-Docker foi baixado quase 2 milhões de vezes. Vários clientes usaram o NVIDIA-Docker para contêiner e executar cargas de trabalho aceleradas por GPU.
A NVIDIA oferece contêineres acelerados por GPU via NVIDIA GPU Cloud (NGC) para uso em sistemas DGX, infraestrutura de nuvem pública e até mesmo estações de trabalho locais com GPUs. A NVIDIA-Docker tem sido a tecnologia subjacente essencial para essas iniciativas.
A adoção de tecnologias de contêineres diferentes do Docker para um conjunto de casos de uso em constante evolução para cargas de trabalho de DL e HPC, entre outras, nos levou a repensar fundamentalmente nossa arquitetura existente do NVIDIA-Docker. Nosso objetivo principal buscava a extensibilidade não apenas em vários tempos de execução de contêineres, mas também em sistemas de orquestração de contêineres.
O NVIDIA Container Runtime apresentado aqui é o nosso tempo de execução do container de reconhecimento de GPU de próxima geração. É compatível com a especificação Open Containers Initiative (OCI) usada pelo Docker, CRI-O e outras tecnologias de contêineres populares.
Você aprenderá sobre os componentes do NVIDIA Container Runtime e como ele pode ser estendido para suportar várias tecnologias de contêiner. Vamos examinar a arquitetura e os benefícios do novo tempo de execução, mostrar alguns dos novos recursos e examinar alguns exemplos de implantação de aplicativos acelerados por GPU usando o Docker e o LXC.
Tempo de Execução do Contêiner NVIDIA
A NVIDIA projetou a NVIDIA-Docker em 2016 para permitir a portabilidade em imagens Docker que aproveitam as GPUs NVIDIA. Ele permitia imagens agnósticas de CUDA do driver e fornecia um wrapper de linha de comando do Docker que montava os componentes do modo de usuário do driver e os arquivos de dispositivos da GPU no contêiner na inicialização.
Durante o ciclo de vida da NVIDIA-Docker, percebemos que a arquitetura não tinha flexibilidade por alguns motivos:
- A forte integração com o Docker não permitiu o suporte de outras tecnologias de contêineres como LXC, CRI-O e outros tempos de execução no futuro
- Queríamos aproveitar outras ferramentas no ecossistema do Docker - por exemplo, o Compose (para gerenciar aplicativos compostos de vários contêineres)
- Suporte GPUs como um recurso de primeira classe em orquestradores como Kubernetes e Swarm
- Melhore o suporte de tempo de execução de contêineres para GPUs - esp. detecção automática de bibliotecas de drivers NVIDIA no nível do usuário, módulos de kernel NVIDIA, pedidos de dispositivos, verificações de compatibilidade e recursos de GPU, como gráficos, aceleração de vídeo
Como resultado, o NVIDIA-Docker reprojetado moveu o suporte de tempo de execução principal para GPUs para uma biblioteca chamada libnvidia-container . A biblioteca depende das primitivas do kernel do Linux e é agnóstica em relação às camadas de tempo de execução mais altas do contêiner. Isso permite a fácil extensão do suporte à GPU em diferentes tempos de execução do contêiner, como Docker, LXC e CRI-O. A biblioteca inclui um utilitário de linha de comando e também fornece uma API para integração em outros tempos de execução no futuro. A biblioteca, as ferramentas e as camadas que construímos para integrar em vários tempos de execução são chamadas coletivamente de Tempo de Execução do Contêiner NVIDIA.
Nas próximas seções, você aprenderá sobre a integração no Docker e no LXC.
Suporte para Docker
Antes de mergulhar na integração do NVIDIA Container Runtime com o Docker, vamos examinar brevemente como a plataforma Docker evoluiu.
Desde 2015, o Docker tem doado componentes-chave de sua plataforma de contêineres, começando com a especificação Open Containers Initiative (OCI) e uma implementação da especificação de um runtime de contêiner leve chamado runc. No final de 2016, o Docker também doou containerdum daemon que gerencia o ciclo de vida do contêiner e envolve o OCI / runc. O containerd daemon lida com transferência de imagens, execução de contêineres (com runc), armazenamento e gerenciamento de rede. Ele foi projetado para ser incorporado em sistemas maiores, como o Docker. Mais informações sobre o projeto estão disponíveis no site oficial .
A Figura 1 mostra como o contêiner-libnvidia se integra ao Docker, especificamente na runc camada. Usamos um gancho de pré-início OCI customizado chamado nvidia-container-runtime-hook para runc ativar os contêineres de GPU no Docker (mais informações sobre ganchos podem ser encontradas na especificação de tempo de execução do OCI ). A adição do gancho de pré-início ao runc requer que registremos um novo tempo de execução compatível com OCI com o Docker (usando a opção –runtime ). No momento da criação do contêiner, o gancho de pré-início verifica se o contêiner está habilitado para GPU (usando variáveis de ambiente) e usa a biblioteca de tempo de execução do contêiner para expor as GPUs NVIDIA ao contêiner.
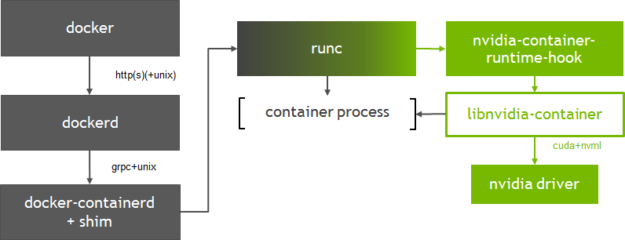
Figura 1. Integração do NVIDIA Container Runtime with Docker
A integração na runc camada também permite flexibilidade para suportar outros tempos de execução de OCI, como o CRI-O. Versão 1.1 do containerd suporte adicionado para o Container Runtime Interface (CRI) no Kubernetes; Na semana passada, o Kubernetes anunciou a disponibilidade geral da containerd integração através do plugin CRI. A nova arquitetura do tempo de execução da NVIDIA pode suportar facilmente qualquer opção de tempo de execução com o Kubernetes. Esse nível de flexibilidade é importante, pois trabalhamos em conjunto com a comunidade para habilitar o suporte a GPU deprimeira classe no Kubernetes.
variáveis ambientais
O NVIDIA Container Runtime usa variáveis de ambiente em imagens de contêiner para especificar um contêiner acelerado por GPU.
- NVIDIA_VISIBLE_DEVICES: controla quais GPUs estarão acessíveis dentro do contêiner. Por padrão, todas as GPUs estão acessíveis ao contêiner.
- NVIDIA_DRIVER_CAPABILITIES: controla quais recursos do driver (por exemplo, computação, gráficos) são expostos ao contêiner.
- NVIDIA_REQUIRE_ *: uma expressão lógica para definir as restrições (por exemplo, capacidade mínima de CUDA, driver ou computação) nas configurações suportadas pelo container.
Se nenhuma variável de ambiente for detectada (na linha de comando do Docker ou na imagem), o padrão runc será usado. Você pode encontrar mais informações sobre essas variáveis de ambiente no NVIDIA Container Runtime documentação . Essas variáveis de ambiente já estão definidas nos contêineres CUDA oficiais da NVIDIA.
Instalação
Seu sistema deve atender aos seguintes pré-requisitos para começar a usar o NVIDIA Container Runtime with Docker.
- Versão suportada do Docker para sua distribuição. Siga as instruções oficiais do Docker.
-
O driver mais recente da NVIDIA. Use o gerenciador de pacotes para instalar o
cuda-driverspacote ou use o instalador no site de downloads do driver . Observe que o uso docuda-driverspacote pode não funcionar nos sistemas LTS do Ubuntu 18.04.
Para começar a usar o NVIDIA Container Runtime with Docker, use os pacotes do instalador nvidia-docker2 ou configure manualmente o tempo de execução com o Docker Engine. O nvidia-docker2 pacote inclui um daemon.json arquivo personalizado para registrar o tempo de execução da NVIDIA como padrão com o Docker e um script para compatibilidade com versões anteriores do nvidia-docker 1.0.
Se você tiver o nvidia-docker 1.0 instalado, será necessário removê-lo e quaisquer contêineres de GPU existentes antes de instalar o tempo de execução da NVIDIA. Note que os seguintes passos de instalação se aplicam às distribuições Debian e seus derivados.
$ docker volume ls - q - f driver = nvidia - docker | xargs - r - I {} - n1 docker ps - q - a - f volume = {} | xargs - r docker rm - f $ sudo apt - get purge - y nvidia - docker
Agora, vamos adicionar os repositórios de pacotes e atualizar o índice do pacote.
$ curl - s - L https : //nvidia.github.io/nvidia-docker/gpgkey | \ sudo apt - key add - $ distribution = $ (. / etc / os - release ; echo $ ID $ VERSION_ID ) $ curl - s - L https : //nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \ sudo tee / etc / apt / sources . lista . d / nvidia - docker . Lista $ sudo apt - obter atualização
Em seguida, instale os vários componentes usando o nvidia-docker2pacote e recarregue a configuração do daemon do Docker.
$ sudo apt - obter instalar - y nvidia - docker2 $ sudo pkill - SIGHUP dockerd
Execute o seguinte utilitário de linha de comando (CLI) para verificar se o driver e o tempo de execução da NVIDIA foram instalados corretamente em seu sistema (fornecidos como parte dos pacotes do instalador). A CLI de tempo de execução fornece informações sobre o driver e os dispositivos detectados no sistema. Neste exemplo, a biblioteca de tempo de execução detectou e enumerou corretamente 4 NVIDIA Tesla V100s no sistema.
$ sudo nvidia - container - cli - load - informações sobre o kmods Versão NVRM : 396.26 Versão CUDA : 9.2 Device Index : 0 Device Minor : 2 Modelo : Tesla V100 - SXM2 - 16GB GPU UUID : GPU - e354d47d - 0b3e-4128 - 74bf - f1583d34af0e Localização do ônibus : 00000000 : 00 : 1b . 0 arquitetura : 7,0 Dispositivo Index : 1 dispositivo Minor : 0 Modelo : Tesla V100 - SXM2 - 16GB GPU UUID : GPU - 716346f4 - da29 - 392A - c4ee - b9840ec2f2e9 Bus Localização : 00000000 : 00 : 1c . 0 arquitetura : 7,0 Dispositivo Index : 2 dispositivo Menor : 3 Modelo : Tesla V100 - SXM2 - 16GB GPU UUID : GPU - 9676587f - b418 - ee6b - 15ac - 38470e1278fb Bus Localização : 00000000 : 00 : 1d . 0 arquitetura : 7,0 Índice do dispositivo : 3 Dispositivo menor : 2 Modelo : Tesla V100 - SXM2 - GPU de 16GB UUID : GPU - 2370332b - 9181 - d6f5 - 1f24 - 59d66fc7a87e Localização do ônibus : 00000000 : 00 : 1e . 0 arquitetura : 7,0
A versão CUDA detectada por nvidia-container-cli verifica se o driver NVIDIA instalado no seu host é suficiente para executar um contêiner com base em uma versão específica do CUDA. Se houver uma incompatibilidade, o tempo de execução não iniciará o contêiner. Mais informações sobre compatibilidade e requisitos mínimos de driver para CUDA estão disponíveis aqui .
Agora, vamos tentar executar um contêiner de GPU com o Docker. Este exemplo puxa o contêiner NVIDIA CUDA disponível no repositório do Docker Hub e executa o nvidia-smi comando dentro do contêiner.
$ sudo docker run - rm - tempo de execução = nvidia - ti nvidia / cuda root @ d6c41b66c3b4 : / # nvidia - smi Domingo 20 de maio 22 : 06 : 13 2018 + ------------------------------- ---------------------------------------------- + | NVIDIA - SMI 396.26 Versão do Driver : 396.26 | | ------------------------------- + ----------------- ----- + ---------------------- + | Persistência do nome da GPU - M | Bus - Id Disp . A | Volatile Uncorr . ECC | | Fan Temp Perf Pwr : Uso / Boné | Memória - Uso | GPU - Util Compute M . | | =============================== + ================= ===== + ====================== | | 0 Tesla V100 - SXM2 ... Em | 00000000 : 00 : 1B . 0 desligado | Off | | N / A 41C P0 34W / 300W | 0 MiB / 16160 MiB | 0 % padrão | + ------------------------------- + ----------------- ----- + ---------------------- + | 1 Tesla V100 - SXM2 ... On | 00000000 : 00 : 1C . 0 desligado | Off | | N / A 39C P0 35W / 300W | 0 MiB / 16160 MiB | 0 % Padrão | + ------------------------------- + ----------------- ----- + ---------------------- + | 2 Tesla V100 - SXM2 ... On | 00000000 : 00 : 1D . 0 desligado | Off | | N / A 39C P0 38W / 300W | 0 MiB / 16160 MiB | 0 % padrão | + ------------------------------- + ----------------- ----- + ---------------------- + | 3 Tesla V100 - SXM2 ... On | 00000000 : 00 : 1E . 0 desligado | 0 | | N / A 42C P0 38W / 300W | 0 MiB / 16160 MiB | 0 % padrão | + ------------------------------- + ----------------- ----- + ---------------------- + + ------------------------------------------------- ---------------------------- + | Processos : Memória GPU | | Tipo de PID da GPU Nome do processo Uso | | ================================================= ============================ | | Nenhum processo em execução encontrado | + ------------------------------------------------- ---------------------------- +
Executando Contêineres GPU
Vamos agora examinar alguns exemplos de execução de aplicativos de GPU mais complexos. A NVIDIA oferece uma variedade de contêineres pré-construídos para aprendizado profundo e HPC no registro NGC .
Recipiente de Estrutura de Aprendizagem Profunda
Este exemplo treina uma rede neural profunda usando o contêiner de estrutura de aprendizado profundo PyTorch disponível no NGC. Você precisará abrir uma conta NGC gratuita para acessar a última estrutura de aprendizado profundo e os contêineres HPC. A documentação do NGC descreve as etapas necessárias para começar.
Este exemplo usa a NVIDIA_VISIBLE_DEVICESvariável, para expor apenas duas GPUs ao contêiner.
$ sudo docker run - it - tempo de execução = nvidia - shm - size = 1g - e NVIDIA_VISIBLE_DEVICES = 0 , 1 - rm nvcr . io / nvidia / pytorch : 18.05 - py3 Copyright ( c ) Instituto de Pesquisa Idiap 2006 ( Samy Bengio ) Copyright ( c ) 2001 - 2004 Instituto de Pesquisa Idiap ( Ronan Collobert , Samy Bengio , Johnny Mariethoz ) Todos os direitos reservados . Vários arquivos incluem modificações ( c ) NVIDIA CORPORATION . Todos os direitos reservados . As modificações da NVIDIA são cobertas pelos termos da licença que se aplicam ao projeto ou arquivo subjacente .
Execute o nvidia-smi comando dentro do contêiner para verificar se apenas duas GPUs estão visíveis.
root @ 45cebefa1480 : / workspace # nvidia-smi Seg Mai 28 07 : 15 : 39 2018 + ------------------------------------------------- ---------------------------- + | NVIDIA - SMI 396.26 Versão do Driver : 396.26 | | ------------------------------- + ----------------- ----- + ---------------------- + | Persistência do nome da GPU - M | Bus - Id Disp . A | Volatile Uncorr . ECC | | Fan Temp Perf Pwr : Uso / Boné | Memória - Uso | GPU - Util Compute M . | | =============================== + ================= ===== + ====================== | | 0 Tesla V100 - SXM2 ... Em | 00000000 : 00 : 1B . 0 desligado | 0 | | N / A 39C P0 36W / 300W | 0 MiB / 16160 MiB | 0 % padrão | + ------------------------------- + ----------------- ----- + ---------------------- + | 1 Tesla V100 - SXM2 ... On | 00000000 : 00 : 1C . 0 desligado | 0 | | N / A 38C P0 35W / 300W | 0 MiB / 16160 MiB | 0 % padrão | + ------------------------------- + ----------------- ----- + ---------------------- + + ------------------------------------------------- ---------------------------- + | Processos : Memória GPU | | Tipo de PID da GPU Nome do processo Uso | | ================================================= ============================ | | Nenhum processo em execução encontrado | + ------------------------------------------------- ---------------------------- + root @ 45cebefa1480 : / workspace #
Tente executar o exemplo de treinamento MNIST incluído no contêiner:
root @ 45cebefa1480 : / workspace / examples / mnist # python main.py Como baixar http : //yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz Como fazer o download http : //yann.lecun.com/ exdb / mnist / rótulo-de-trens-idx1-ubyte.gz Download http : //yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz Download http : //yann.lecun.com/exdb/ mnist / t10k-labels-idx1-ubyte.gz Processando ... Concluído ! principal . py : 68 : UserWarning : Implícito A escolha de dimensão para o log_softmax foi descontinuada . Altere a chamada para incluir dim = X como um argumento . voltar F . log_softmax ( x ) main . py : 90 : UserWarning : índice inválido de um tensor 0 - dim . Este será um erro no PyTorch 0.5 . Use tensor . item () para converter um 0 - dimor tensor para um número 100 do Python . * batch_idx / len ( train_loader ), perda . dados [ 0 ])) Trem Epoch : 1 [ 0 / 60000 ( 0 %)] Perda : 2,373651 Trem Epoch : 1 [ 640 / 60000 ( 1 %)] Perda : 2,310517 Trem Epoch : 1 [ 1280 / 60000 ( 2 %)] Perda : 2,281828 Trem Epoch : 1 [ 1920 / 60000 ( 3 %)] Perda : 2,315808 Trem Epoch : 1 [ 2560 / 60000 ( 4 %)] Perda : 2,235439 Trem Epoch : 1 [ 3200 / 60000 ( 5 %)] Perda : 2.234249 A época do trem : 1 [ 3840 / 60000 ( 6 %)] Perda : 2,226109 Trem Epoch : 1 [ 4480 / 60000 ( 7 %)] Perda : 2,228646 Trem Epoch : 1 [ 5120 / 60000 ( 9 %)] Perda : 2,132811
Contêiner de Gráficos OpenGL
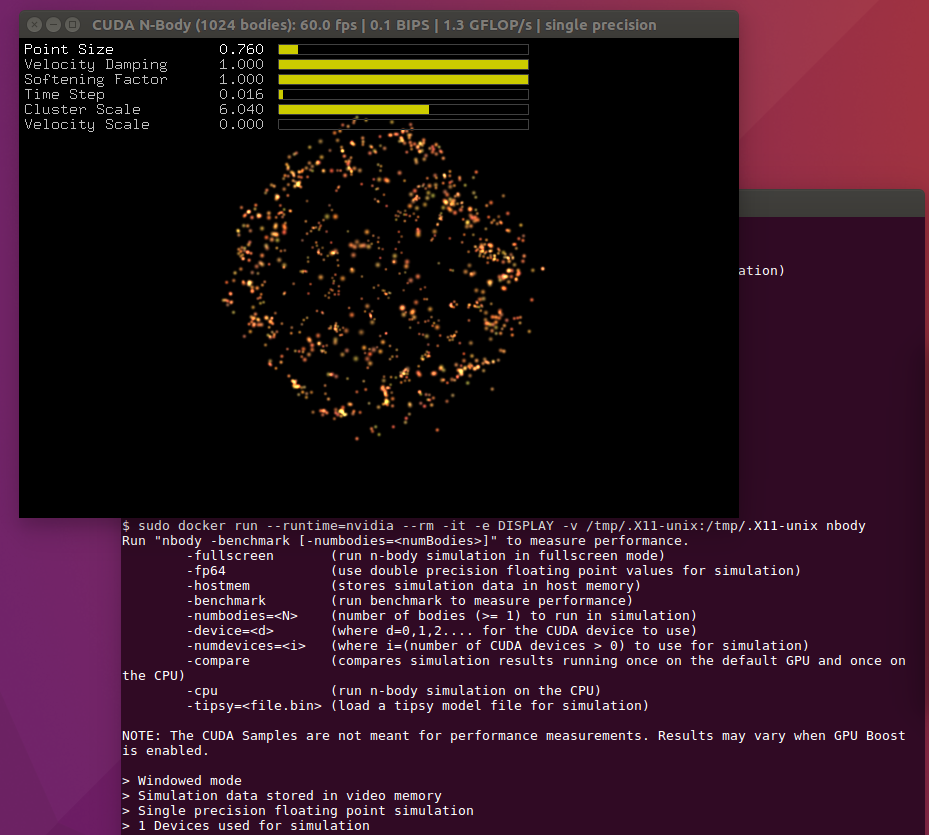
Conforme discutido nas seções anteriores, o NVIDIA Container Runtime agora fornece suporte para executar aplicativos OpenGL e EGL. O próximo exemplo constrói e executa a simulação N-body usando o OpenGL. Use o Dockerfile de amostra disponível no NVIDIA GitLab para criar o contêiner.
Copie o Dockerfile e construa a amostra N-body
$ docker build - t nbody .
Permitir que o usuário root acesse o servidor X em execução
$ xhost + si : localuser : root
Execute a amostra N-body
$ sudo docker run - tempo de execução = nvidia - ti - rm - e DISPLAY - v / tmp /. X11 - unix : / tmp / . X11 - unix nbody
Docker Compose
O exemplo final usa o Docker Compose para mostrar como é fácil lançar vários contêineres de GPU com o NVIDIA Container Runtime. O exemplo lançará 3 contêineres - a amostra N-body com OpenGL, uma amostra EGL ( peglgears de Mesa) e um contêiner simples que executa o comando nvidia-smi .
Instalar o Docker Compose
$ sudo curl - L https : //github.com/docker/compor/releases/download/1.21.2/docker-compose-`uname -s`-`uname -m` -o / usr / local / bin / docker -compose $ sudo chmod + x / usr / local / bin / docker - compor
Clone as amostras disponíveis no NVIDIA Gitlab
$ git clone https : //gitlab.com/nvidia/samples.git
Escreva um docker-compose.yml para especificar os três contêineres e os ambientes. Copie o seguinte usando um editor de texto de sua escolha:
versão : '2.3' serviços : nbody : build : samples / cudagl / ubuntu16 . 04 / nbody tempo de execução : nvidia ambiente : - DISPLAY volumes : - / tmp / . X11 - unix : / tmp / . X11 - unix peglgears : build : samples / opengl / ubuntu16 . 04 / peglgears tempo de execução : nvidia nvsmi : imagem : ubuntu : 18.04 runtime : nvidia ambiente : - NVIDIA_VISIBLE_DEVICES = all comando : nvidia - smi
Permitir que o usuário root acesse o servidor X em execução (para o exemplo N-body )
$ xhost + si : localuser : root
Finalmente, inicie os contêineres
$ sudo docker - componha
A saída do seu console pode aparecer como abaixo
Construindo nbody Passo 1 / 6 : DE nvidia / cudagl : 9,0 - de base - ubuntu16 . 04 ---> b6055709073e Passo 2 / 6 : ENV NVIDIA_DRIVER_CAPABILITIES $ { NVIDIA_DRIVER_CAPABILITIES }, exibir ---> Usando cache de ---> ebd1c003a592 Passo 3 / 6 : RUN apt - obter update && apt - obter instalar - y - não - instalar - recomenda cuda - samples - $ CUDA_PKG_VERSION && rm - rf / var / lib / apt / lists / * ---> Usando o cache ---> 1987dc2c1bbc Passo 4/6: WORKDIR / usr / local / cuda / samples / 5_Simulations / nbody ---> Usando o cache ---> de7af4fbb03e Passo 5/6: Executar ---> Usando o cache ---> a6bcfb9a4958 Etapa 6/6: CMD ./nbody ---> Usando o cache ---> 9c11a1e93ef2 Construído com sucesso 9c11a1e93ef2 Tagged com sucesso ubuntu_nbody: latest AVISO: A imagem para o serviço nbody foi construída porque ainda não existia. Para reconstruir essa imagem, você deve usar o `docker-compose build` ou o` docker-compose up -build`. Iniciando o ubuntu_nbody_1 ... pronto Iniciando o ubuntu_nvsmi_1 ... concluído A partir de ubuntu_peglgears_1 ... concluído Anexando ao ubuntu_nvsmi_1, ubuntu_peglgears_1, ubuntu_nbody_1 ubuntu_nvsmi_1 saiu com o código 0 peglgears_1 | peglgears: versão EGL = 1,4 peglgears_1 | peglgears: EGL_VENDOR = NVIDIA peglgears_1 | 246404 quadros em 5,0 segundos = 49280,703 FPS O ubuntu_peglgears_1 saiu com o código 0
Suporte para contêineres GPU com LXC
O Linux Containers (ou LXC ) é uma ferramenta de virtualização no nível do sistema operacional para criar e gerenciar contêineres de sistema ou de aplicativo. Versões anteriores do Docker usavam o LXC como a tecnologia de tempo de execução do contêiner subjacente. O LXC oferece um conjunto avançado de ferramentas para gerenciar contêineres (por exemplo, modelos, opções de armazenamento, dispositivos de passagem, autostart etc.) e oferece ao usuário muito controle. Nas referências, fornecemos um link para uma palestra do GTC 2018 sobre LXC por engenheiros da Canonical e Cisco nas referências no final deste post.
O LXC suporta contêineres sem privilégios (usando o recurso namespaces do usuário no kernel do Linux). Isso se torna uma grande vantagem no contexto da implantação de contêineres em ambientes HPC, em que os usuários podem não ter direitos administrativos para executar contêineres. O LXC também suporta a importação de imagens do Docker e exploraremos um exemplo com mais detalhes abaixo.
A NVIDIA continua a trabalhar de perto com a comunidade LXC no upstreaming de patches para adicionar suporte à GPU. O LXC 3.0.0 lançado no início de abril inclui suporte para GPUs usando o tempo de execução NVIDIA. Para mais informações e uma demonstração, veja este post de notícias da Canonical.
A Figura 2 mostra como a biblioteca de tempo de execução do contêiner ( libnvidia-container ) se integra ao LXC.
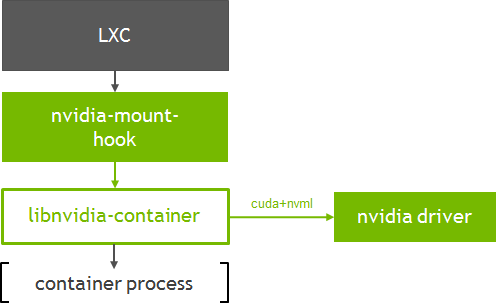
Vamos analisar a execução de um contêiner CUDA simples com o LXC. Este exemplo mostra como o modelo LXC OCI padrão pode ser usado para criar um contêiner de aplicativo a partir de imagens OCI, como aquelas disponíveis no Docker Hub (usando ferramentas como skopeo e umoci ).
Primeiro, vamos configurar os repositórios para as ferramentas:
$ sudo add - apt - repositório ppa : ubuntu - lxc / lxc - stable $ sudo apt - adicionar - repositório ppa : projectatomic / ppa
Instale o LXC e ferramentas dependentes como skopeo:
$ apt - obter instalar libpam - cgfs lxc - utils lxcfs lxc - modelos skopeo skopeo - contentores jq libnvidia - container - ferramentas
Setup umoci:
$ sudo curl - fsSL - o / usr / local / bin / umoci https : //github.com/openSUSE/umoci/releases/download/v0.4.0/umoci.amd64 $ sudo chmod ugo + rx / usr / local / bin / umoci
Configure o usuário, ids de grupo e interfaces ethernet virtuais para cada usuário. Consulte a documentação do LXC sobre como criar contêineres sem privilégios. Os scripts de amostra são fornecidos aqui por conveniência.
$ sudo curl - fsSL - o / usr / local / bin / gerar - lxc - perms https : //gist.githubusercontent.com/3XX0/ef77403389ffa1ca85d4625878706c7d/raw/4f0d2c02d82236f74cf668c42ee72ab06158d1d2/generate-lxc-perms.sh $ sudo chmod ugo + rx / usr / local / bin / generate - lxc - perms $ sudo curl - fsSL - o / usr / local / bin / gerar - lxc - configuração https : //gist.githubusercontent.com/3XX0/b3e2bd829d43104cd120f4258c4eeca9/raw/890dc720e1c3ad418f96ba8529eae028f01cc994/generate-lxc-config.sh $ sudo chmod ugo + rx / usr / local / bin / generate - lxc - config
Agora, configure o suporte da GPU para cada contêiner:
$ sudo tee / usr / share / lxc / config / common . conf . d / nvidia . conf <<< 'lxc.hook.mount = / usr / share / lxc / hooks / nvidia' $ sudo chmod ugo + r / usr / partilha / lxc / config / common . conf . d / nvidia . conf
Como uma configuração única, configure as permissões e a configuração como um usuário comum:
$ sudo generate - lxc - perms $ generate - lxc - config
Use lxc-create para baixar e criar um contêiner de aplicativo CUDA a partir da imagem CUDA disponível no repositório do Docker Hub da NVIDIA.
$ LXC - criar - t oci CUDA - - u janela de encaixe : // nvidia / CUDA Obtendo assinaturas de origem da imagem Copiar blob sha256 : 297061f60c367c17cfd016c97a8cb24f5308db2c913def0f85d7a6848c0a17fa 41,03 MB / 41.03 MB [================ ======================================] 0s Copiar sha256 blob : e9ccef17b516e916aa8abe7817876211000c27150b908bdffcdeeba938cd004c 850 B / 850 B [================================================= ===========] 0s Copiar sha256 blob : dbc33716854d9e2ef2de9769422f498f5320ffa41cb79336e7a88fbb6c3ef844 621 B / 621 B [======================================= =====================] 0s Copiar sha256 blob : 8fe36b178d25214195af42254bc7d5d64a269f654ef8801bbeb0b6a70a618353 851 B / 851 B [================ ======================================================= 0s Copiando blob sha256 : 686596545a94a0f0bf822e442cfd28fiênciasa769f28e5f4018d7c24576dc6c3aac 169 B / 169 B [================================================= ===========] 0s Copiar blob sha256 : aa76f513fc89f79bec0efef655267642eba8deac019f4f3b48d2cc34c917d853 6,65 MB / 6.65 MB [========================== ==============================] 0s Copiando sha256 blob : c92f47f1bcde5f85cde0d7e0d9e0caba6b1c9fcc4300ff3e5f151ff267865fb9 397,29 KB / 397,29 KB [======= ========================================================= 0s Copiando blob sha256 : 172daef71cc32a96c15d978fb01c34e43f33f05d8015816817cc7d4466546935 182 B / 182 B [============================================= ===============] 0s Copiar blob sha256 : e282ce84267da687f11d354cdcc39e2caf014617e30f9fb13f7711c7a93fb414 449,41 MB / 449.41 MB [====================== ==============================] 8s Copiar blob sha256 : 91cebab434dc455c4a9faad8894711a79329ed61cc3c08322285ef20599b4c5e 379,37 MB / 552.87 MB [======= ==============================> -----------------] Escrita manifestar-se para o destino da imagem Armazenando assinaturas Descompactando os rootfs • sem raiz { dev / agpgart } criando arquivo vazio no lugar do dispositivo 10 : 175 • sem raiz { dev / audio } criando arquivo vazio no lugar do dispositivo 14 : 4 • { dev / audio1 } sem raiz criando arquivo vazio no lugar de dispositivo 14 : 20
Como usuário comum, podemos executar o nvidia-smi interior do contêiner:
$ lxc - executa cuda root @ cuda : / # nvidia - smi seg 28 de maio 21 : 48 : 57 2018 + ------------------------------- ---------------------------------------------- + | NVIDIA - SMI 396.26 Versão do Driver : 396.26 | | ------------------------------- + ----------------- ----- + ---------------------- + | Persistência do nome da GPU - M | Bus - Id Disp . A | Volatile Uncorr . ECC | | Fan Temp Perf Pwr : Uso / Boné | Memória - Uso | GPU - Util Compute M . | | =============================== + ================= ===== + ====================== | | 0 Tesla V100 - SXM2 ... Em | 00000000 : 00 : 1B . 0 desligado | 0 | | N / A 40C P0 36W / 300W | 0 MiB / 16160 MiB | 0 % padrão | + ------------------------------- + ----------------- ----- + ---------------------- + | 1 Tesla V100 - SXM2 ... On | 00000000 : 00 : 1C . 0 desligado | 0 | | N / A 39C P0 35W / 300W | 0 MiB / 16160 MiB | 0 % padrão | + ------------------------------- + ----------------- ----- + ---------------------- + | 2 Tesla V100 - SXM2 ... On | 00000000 : 00 : 1D . 0 desligado | 0 | | N / A 39C P0 38W / 300W | 0 MiB / 16160 MiB | 1 % padrão | + ------------------------------- + ----------------- ----- + ---------------------- + | 3 Tesla V100 - SXM2 ... ligado | 00000000 : 00 : 1E . 0 desligado | 0 | | N / A 40C P0 38W / 300W | 0 MiB / 16160 MiB | 1 % padrão | + ------------------------------- + ----------------- ----- + ---------------------- + + ------------------------------------------------- ---------------------------- + | Processos : Memória GPU | | Tipo de PID da GPU Nome do processo Uso | | ================================================= ============================ | | Nenhum processo em execução encontrado | + ------------------------------------------------- ---------------------------- +
Conclusão
Este post aborda o Tempo de Execução do Contêiner da NVIDIA e como ele pode ser facilmente integrado ao ecossistema de tempo de execução e orquestração do contêiner para ativar o suporte à GPU. Comece a construir e executar contêineres de GPU com ele hoje mesmo! Pacotes de instaladores estão disponíveis para uma variedade de distribuições Linux. O Nvidia-Docker 1.0 está obsoleto e não é mais suportado ativamente. Encorajamos os usuários a atualizar para o novo tempo de execução da NVIDIA ao usar o Docker. O roteiro futuro inclui uma série de recursos interessantes, incluindo suporte para Vulkan, MPS CUDA, drivers em contêiner e muito mais.
Se você estiver executando contêineres em provedores de serviços de nuvem pública, como Amazon AWS ou Google Cloud, a NVIDIA oferece imagens de máquinas virtuais que incluem todos os componentes necessários, incluindo o NVIDIA Container Runtime para começar.
Se você tiver dúvidas ou comentários, por favor, deixe-os abaixo na seção de comentários. Para questões técnicas sobre instalação e uso, recomendamos iniciar uma discussão nos fóruns da NVIDIA Container Technologies .
Referências
[1] Assista a uma série de três partes sobre como instalar o NVIDIA Container Runtime e usá-lo com contêineres NGC ( https://www.youtube.com/watch?v=r3LrCnou1K4 )
[2] Usando o Container para GPU Workloads (GTC 2018 fala sobre o LXC) http://on-demand-gtc.gputechconf.com/gtc-quicklink/a6WCcp
[3] Perguntas frequentes estão disponíveis na documentação https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions
Donate to Site

Renato
Developer